
Neural What? My LLM bill is down to a sixth - by no longer paying per token.


You might have read recently on this blog that my procurement preferences for hank.parts are basically
- EU,
- (self hosted) open source,
- UK/CH,
- Rest of the world,
in this order.
This article is a "rest of the world" case where my first impression of both the concept and the product overwhelmed me to a point where I thought I was taking part in something legally questionable. A rare "wait, this sounds too good to be true" moment that actually was... True.
What is going on with tokens?
I am a big fan of open weight models for daily tasks, API stuff and coding, which I either infer via Nebius or, gritting my teeth, OpenRouter. Both operate on input and output pricing where each model is metered per million tokens consumed.
It's either that or you are on some monthly subscription giving you some magic usage quotas that reset at the full moon or at 12:34 every other Friday in a non-summer month in the northern hemisphere. These plans can be quite restrictive with API usage, where the big three force you into token-based metering again if you want to interact with the models outside their tooling... Making these frontier model usage plans, which surely will rise in price or will see quota adjustments in the very near future, extremely expensive via API token-based metering. For example: Claude Opus 4.8 is 5 USD per million input tokens and a whopping 25 USD per million output tokens on OpenRouter.
So, that's the status quo. Pay for a plan and pray for included API access or pay for the tokens you actually consume. At least that's what I thought until more or less a month ago.
Lurking on LinkedIn pays off
sometimes
Then I read a post from Vito Botta, whom I highly recommend following, on LinkedIn:
Vito Botta on LinkedIn
NeuralWatt? Never heard of it. Energy-based metering? Okay?! Vito explained the concept already well enough, so I will jump straight to the cost comparison:
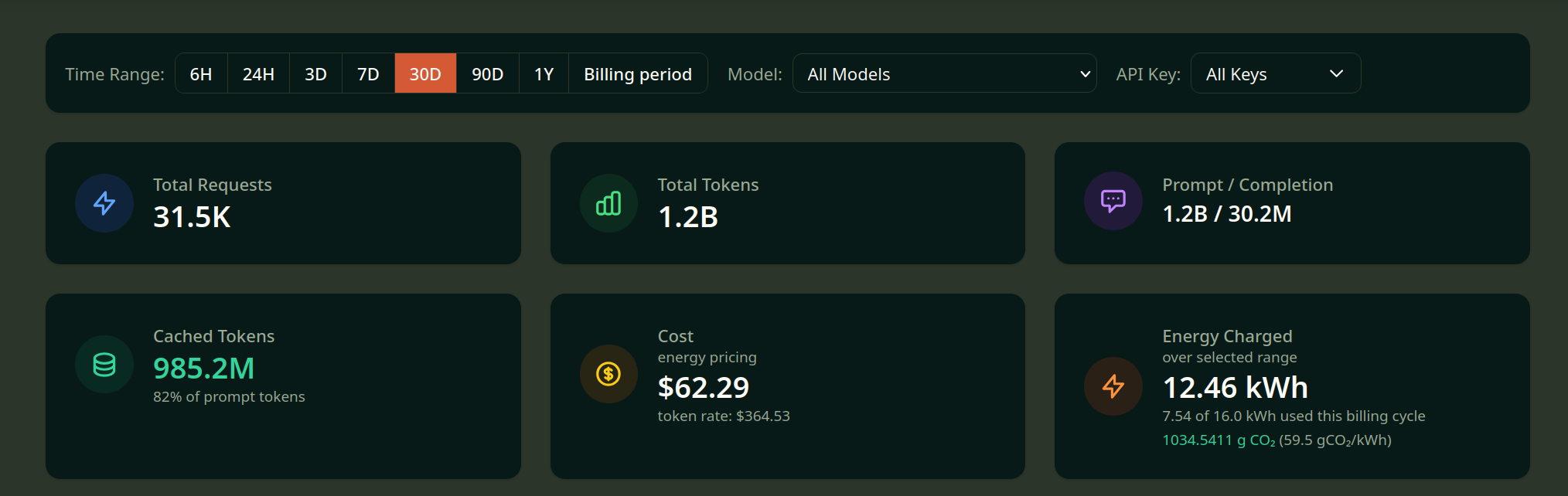
Price comparison per model
| Modell | Energy $ | Token $ | Factor | Cached |
|---|---|---|---|---|
| Kimi-K2.7-Code | 30.41 | 174.13 | 5.7× | 92 % |
| Kimi-K2.6 | 23.98 | 119.09 | 5.0× | 92 % |
| Qwen3.6-35B-A3B | 4.67 | 24.42 | 5.2× | 1 % |
| qwen3.6-35b-fast | 2.00 | 41.56 | 20.8× | 9 % |
| glm-5.2 | 1.03 | 4.72 | 4.6× | 86 % |
| kimi-k2.6 | 0.19 | 0.57 | 3.0× | 4 % |
| Qwen3.5-397B | 0.02 | 0.12 | 4.8× | – |
NeuralWatt from the US of A offers both token and energy-based billing so I can directly compare my savings, a whopping 82.9% on average and 95.2% for Qwen3.6-35b-fast, which is mind-blowing to me. I would have paid 302.32 USD more for the same usage on the same platform with token-based metering.
Also, look at these cache numbers for the Kimi models I use for coding! NeuralWatt seem to have some very efficient caching going on for repeat input and have no problem with forwarding the cost savings on to the customer. Their token-based pricing even has separate "cached" rates, giving the input/output pricing duo some company.
All this is very exciting. A new way to meter LLM usage that is aware of energy consumption AND cheaper at the same time?!
Here are some things I noticed over my first month on NeuralWatt:
- Concurrent-request and rate limits can feel restrictive coming from other platforms. Retry mechanisms with exponential backoff have solved my initial problems so far.
- I had to use streaming mode for API responses, since some 524 errors kept popping up for longer answers - all fine since the streaming switch.
- Performance sometimes can feel a bit slow compared to what I was used to from Nebius. Last couple of days especially; growing pains I guess?!
- I didn't see a quick way to obtain a DPA, but I did not look too hard since my NeuralWatt usage is not GDPR-relevant.
- Data retention policy is not strictly ZDR - I guess a cross-request caching trade-off? No training on user data inspires confidence.
Full disclosure part #1: I typed this article into my phone on a sleepless Thursday night and an LLM structured my incoherent ramblings into this final article. Guess which LLM?
Full disclosure part #2: I am a paying NeuralWatt customer and neither I nor my businesses have further associations with NeuralWatt at the time of writing.